CPU缓存模型及伪共享
缓存模型
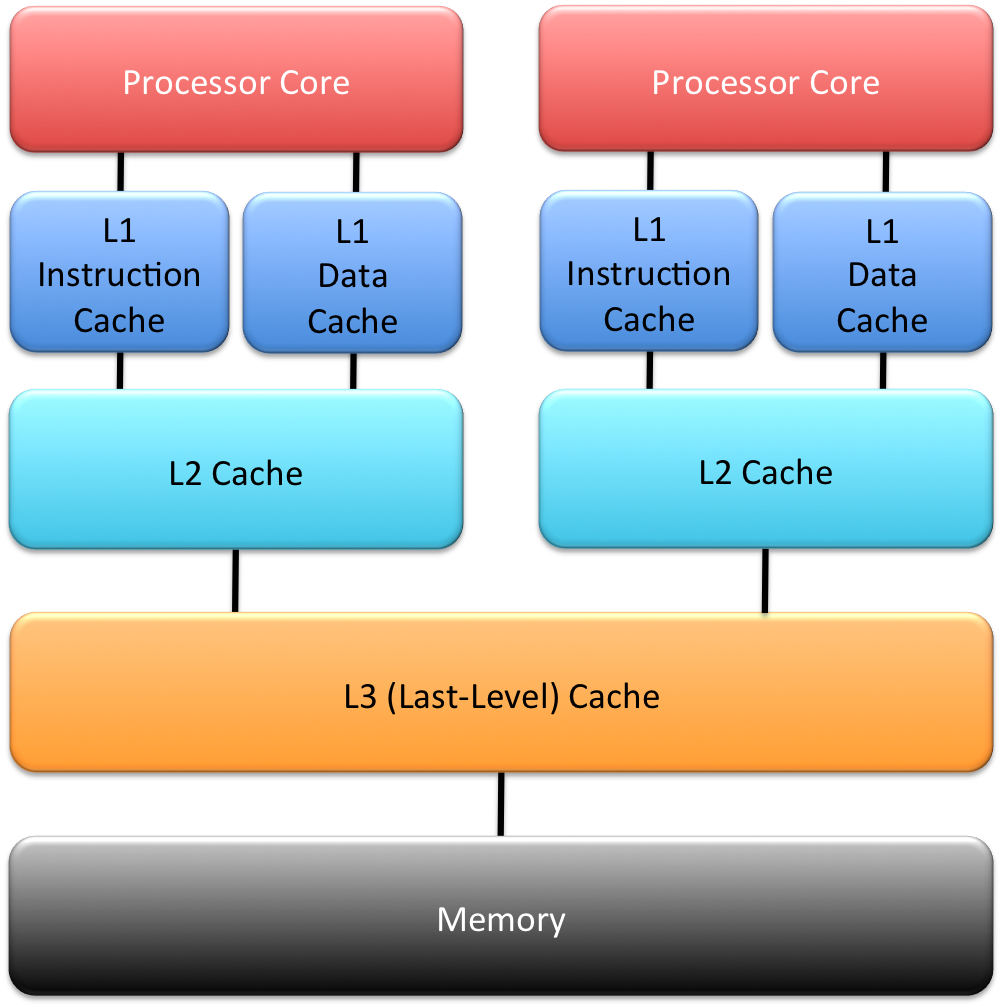
上图是CPU的缓存模型,L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。下面是从CPU访问不同层级数据的时间概念
| Cache Level | 需要的CPU周期 | 需要的时间 |
|---|---|---|
| L1 Cache | 约 3 - 4 cycles | 约 1 ns |
| L2 Cache | 约 10 cycles | 约 3 ns |
| L3 Cache | 约 40 - 45 cycles | 约 15 ns |
| Memory | - | 约 60 - 80 ns |
因此涉及频繁计算的业务场景,要尽量确保数据在L1缓存中
缓存行
Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块地址。CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line
例如,在Java中,一个long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。当访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载相邻的另外7个。如果业务代码连续操作相邻的数组元素,就可以避免CPU频繁的从主存去拉取数据到L1 Cache
下面的例子是测试利用cache line的特性和不利用cache line的特性的效果对比
public class CacheLine {
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
/**
* 连续操作相邻的数据元素,cache line可以多次重复利用
*/
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i++) {
for (int j = 0; j < 8; j++) {
sum = arr[i][j];
}
}
System.out.println("Loop time leveraging cache line effect : " + (System.currentTimeMillis() - marked) + "ms");
/**
* 连续操作不相邻的数据元素,且间隔超过64字节,cache line仅能使用一次,CPU频繁从主存拉取数据到L1 Cache
*/
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 1024 * 1024; j++) {
sum = arr[j][i];
}
}
System.out.println("Loop time not leveraging cache line effect : " + (System.currentTimeMillis() - marked) + "ms");
}
}
从结果看,有将近4倍的性能差距
Loop time leveraging cache line effect : 19ms
Loop time not leveraging cache line effect : 76ms
伪共享 (False Sharing)
伪共享指的是多个线程同时读写同一块物理缓存区域(cache line),导致任何一个线程的写操作都会导致其他线程的CPU L1缓存失效,需要频繁从主存同步数据到L1缓存的性能损失现象
例如下例中多个线程并发更改一个对象数组的对象内部属性
public class FalseSharing implements Runnable {
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
private static ValueNoPadding[] longs;
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for (int i = 1; i < 10; i++) {
System.gc();
final long start = System.currentTimeMillis();
runTest(i);
System.out.println("Thread num " + i + " duration = " + (System.currentTimeMillis() - start));
}
}
private static void runTest(int NUM_THREADS) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longs = new ValueNoPadding[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new ValueNoPadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = 0L;
}
}
public final static class ValueNoPadding {
protected volatile long value = 0L;
}
/**
* Padding solution, to avoid different object in same cache line
*/
public final static class ValuePadding {
protected volatile long value = 0L;
protected long p1, p2, p3, p4, p5, p6, p7;
}
/**
* Supported from jdk 1.8, Need add "-XX:-RestrictContended" jvm parameter
*/
public final static class ValuePaddingWithContend {
@Contended
protected volatile long value = 0L;
}
}
在上例中,ValueNoPadding类仅有一个volatile的long类型变量(8字节),那么ValueNoPadding数组中的多个元素会被放入同一个cache line,在并发修改时会触发cache line的频繁更新,造成伪共享
以下为使用ValueNoPadding类的结果
1Thread num 1 duration = 500
2Thread num 2 duration = 1371
3Thread num 3 duration = 1423
4Thread num 4 duration = 1416
5Thread num 5 duration = 3025
6Thread num 6 duration = 3252
7Thread num 7 duration = 3014
8Thread num 8 duration = 3122
9Thread num 9 duration = 2654
一种解决方案是ValuePadding类,通过增加对象属性来撑满cache line,使得ValuePadding数组的不同元素位于不同的cache line,并发修改时就不会相互影响,这是一种空间换时间的解决思路
以下为使用ValuePadding类的结果,可以看到在多线程的情况下,计算时间有了较大的提升
1Thread num 1 duration = 498
2Thread num 2 duration = 774
3Thread num 3 duration = 851
4Thread num 4 duration = 1095
5Thread num 5 duration = 1648
6Thread num 6 duration = 1949
7Thread num 7 duration = 2134
8Thread num 8 duration = 2289
9Thread num 9 duration = 1961
另外还可以利用jdk 1.8的@Contended注解来更优雅的解决这个问题,参考ValuePaddingWithContend类,jvm会根据这个注解来自动填充cache line。该注解可以加在属性上,就是单独填充属性字段,也可以加在class定义上,就是填充整个对象。该注解还可以设置group参数来使多个属性合并在一起填充,相同group的参数之间不填充(注意,使用@Contended注解时需要添加-XX:-RestrictContended jvm参数,否则不会生效)
以下为使用ValuePaddingWithContend类的结果,性能与ValuePadding类近似,但代码实现更为优雅
1Thread num 1 duration = 462
2Thread num 2 duration = 618
3Thread num 3 duration = 694
4Thread num 4 duration = 877
5Thread num 5 duration = 1053
6Thread num 6 duration = 1197
7Thread num 7 duration = 1313
8Thread num 8 duration = 1541
9Thread num 9 duration = 1709